| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Oracle DB
- oracle
- alias
- Bootstrap
- JavaScript
- HTML
- 모조칼럼
- 부트스트랩
- 제약조건
- sql developer
- 이클립스
- git
- CRUD
- 성적프로그램
- JSP
- github
- rownum
- 한글 인코딩
- SQL
- jQuery
- ||
- group by
- Java
- Oracle SQL
- HTTP Status 500
- 과정평가형
- tomcat
- distinct
- HTTP Status 404
- 답변형 게시판
초급의 끄적거림
[기타] R, Python 입문 본문
+) R, Python 크롤링 해보기
1. 대표적인 인터프리터 방식 R
- 강사님 사이트 [빅데이터]
- 통계를 배워서 통계와 관련된 시각화 작업이 가능함

score 변수에 3을 넣어라 : score <-3
이후에 score를 찾으면 그 score가 3임을 나타냄
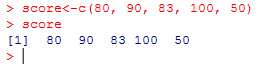
변수 score에 , (콤마)를 사용하여 여러개를 넣을 수가 있음

mean(score) 평균
median(score) 중앙값 : 가운데 있는 값
홀수개이면 정 가운데 값을 중앙값, 짝수이면 정가운데의 양쪽 두개의 값을 가져다가 평균을 내서 중앙값을 계산
var(score) 분산 : 평균값에서 값이 어느 정도 분산되어 있는가
sd(score) 표준편차 : 평균과의 거리 평균

100만이라는 숫자의 평균이 168이고 표준편차가 7인 것의 정규분포도를 height 변수에 넣어라
hist (~~) : 이것의 히스토그램을 만들라
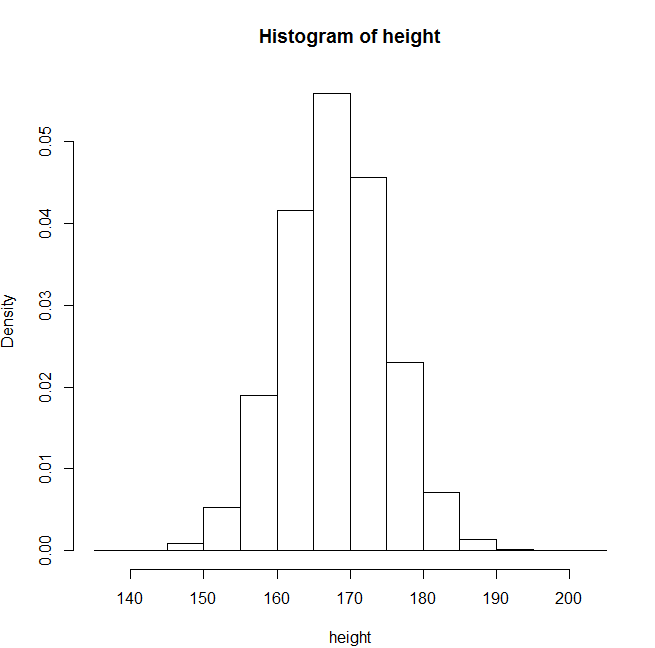
- bigdata 폴더 생성 : 파일 - 작업디렉토리변경 - bigdata
만들어진 히스토그램에 선을 만들어줌


- 히스토그램 저장


2. 워드클라우드 만들기
- 사용하고자하는 텍스트를 bigdata 폴더에 넣어주기
- 별도의 패키지 추가설치
: 1. 명령어로 불러오는 방법 2. 상단의 '패키지들'

- 'Korea' - 'wordcloud' 선택 후 설치

2-1. 비틀즈 'Yesterday'의 가사 워드클라우드
#텍스트 읽기
> lyrics<-scan("yesterday.txt", what="character")
> str(lyrics)
> head(lyrics)
#텍스트 전처리
> grep(",", lyrics)
> grep("\\.", lyrics)
> grep("\\!", lyrics)
> grep("\\?", lyrics)
> lyrics.1<-gsub(",","",lyrics)
> lyrics.1<-gsub("\\.","",lyrics.1)
> lyrics.1<-gsub("\\!","",lyrics.1)
> lyrics.1<-gsub("\\?","",lyrics.1)
#빈도 시각화
> tab.1<-table(lyrics.1)
> tab.2<-sort(tab.1, decreasing=TRUE)
> tab.2a<-tab.2[tab.2>1]
> par(mar=c(4,6,4,4))
> barplot(rev(tab.2a), horiz=TRUE, las=2, main="Beatles' Yesterday", col="lightblue")
#wordcloud 패키지 설치
> library(wordcloud)
> windows(width=4, height=4); par(mar=c(2,2,2,2))
> set.seed(12345)
> wordcloud(words=names(tab.1), freq=tab.1, scale=c(5,0.5), min.freq=1, colors=rainbow(10), random.color=FALSE, random.order=FALSE, rot.per=0.25)


3. 파이썬
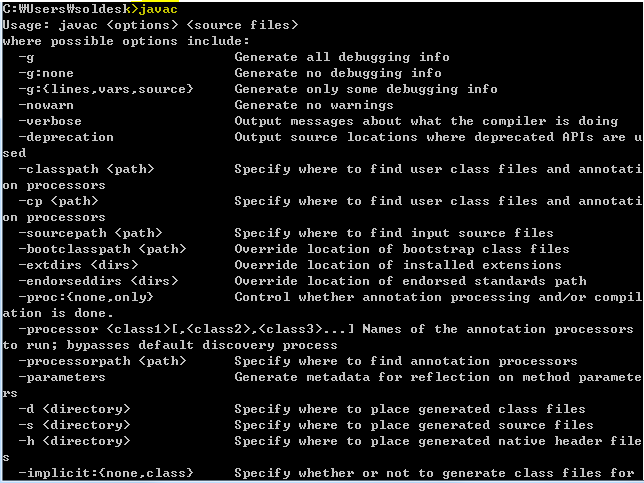
- 자바가 기본적으로 설치가 되어 있어야 사용가능
- cmd - javac로 확인하기
3-1. 텐서플로 기본 개론
- 텐서플로의 텐서는 다차원 숫자 배열형의 데이터이다
- 0차원 텐서는 스칼라, 1차원 텐서는 리스트(벡터), 2차원 텐서는 행렬, 3차원 이상일때는 다차원 행렬
1) 상수, 변수
- tf.Variable() : 학습 시에 업데이트하는 파라미터를 저장하는 변수. 텐서 생성
- tf.global_variables_initializer() : 변수 초기화
2) 플레이스홀더, 피드 딕셔너리
- tf.placeholder() : 구체적인 형태나 값이 정해지지 않은 임시 변수 (속이 빈 상자)
- feed_dict : 플레이스홀더와 실제값을 연결하는 역할. 상자 안에 내용을 채워 넣는 역할
https://www.python.org/downloads/windows/
Python Releases for Windows
The official home of the Python Programming Language
www.python.org


설치 후, cmd 에서 'python --version' 으로 버전 확인 가능
명령어를 사용해서 패키지 설치 후 사용
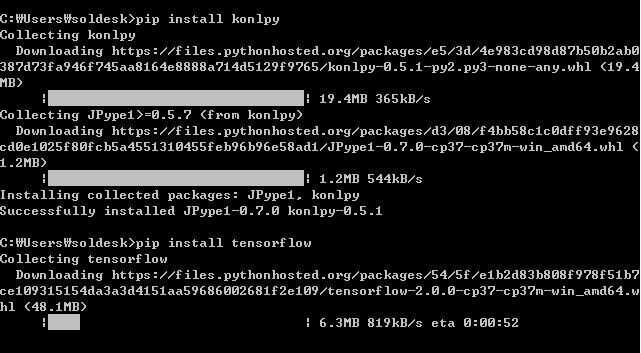
pip install numpy
pip install wordcloud
pip install konlpy
pip install tensorflow